Overtrained Language Models Are Harder to Fine-Tune (과잉 훈련 재앙)
AI/LLM 시리즈 : Catastrophic Overtraining
LLM을 연구하고 개발하는 입장에서 빠르게 소식을 확인하는 것은 매우 중요합니다. 애독하는 AI 타임스에 이번 주 매우 흥미로운 기사가 올라왔습니다. 제가 직접 겪고 있던 고민을 일부나마 설명해줄 수 있을 것 같아 이를 기반으로 포스팅을 작성해보겠습니다.
논문의 핵심 주장
Overtrained Language Models Are Harder to Fine-Tune (Jacob Mitchell Springer et al., 2025)의 요지는 다음과 같습니다.
충분히 잘 학습된 Pretrained model에 SFT(Supervised Fine-Tuning)를 적용하더라도 성능이 오르지 않고 오히려 감소될 수 있다.
연구진은 OLMo-1B 모델을 대상으로 2.3조 토큰과 3조 토큰으로 학습된 모델을 비교했을 때, 3조 토큰 모델이 지시 튜닝 후 여러 벤치마크에서 2~3% 낮은 성능을 보임을 확인했습니다. 이를 재앙적 과훈련(catastrophic overtraining) 이라고 명명했습니다.
이는 개인적으로도 매우 공감되는 현상입니다. 사람들이 좋다고 하는 방법으로 SFT를 진행해도 성능이 오르기는커녕 오히려 감소하는 경우를 실무에서 여러 번 경험했기 때문입니다.
Abstract
대형 언어 모델은 사전 학습 성능이 향상될수록 최종 응용 모델의 성능도 개선될 것이라는 가정 하에 점점 증가하는 토큰 예산으로 학습됩니다. 본 연구는 이 가정에 도전하며, 과도한 사전 학습이 모델을 미세조정하기 어렵게 만들어 최종 성능을 저하시킬 수 있음을 보여줍니다. 통제된 실험과 이론적 분석을 통해, 재앙적 과훈련이 파라미터의 민감도가 체계적으로 증가함에 따라 발생함을 밝히고, 사전 학습 설계에 대한 근본적인 재검토가 필요함을 시사합니다.
실험 방법 및 결과
실험 설계
연구진은 OLMo-1B, OLMo-2-7B, LLM360-Amber-7B 등 다양한 모델을 대상으로 아래 미세조정을 진행하며 분석했습니다.
- Instruction Tuning: Anthropic-HH와 TULU 데이터셋 활용
- 멀티모달 미세조정: LLaVA 프레임워크 활용
사전 학습 토큰 수가 증가함에 따라 in-domain(직접 목표 태스크)과 out-of-domain(일반 평가 태스크) 성능이 어떻게 변화하는지를 체계적으로 분석했습니다.
실험 결과
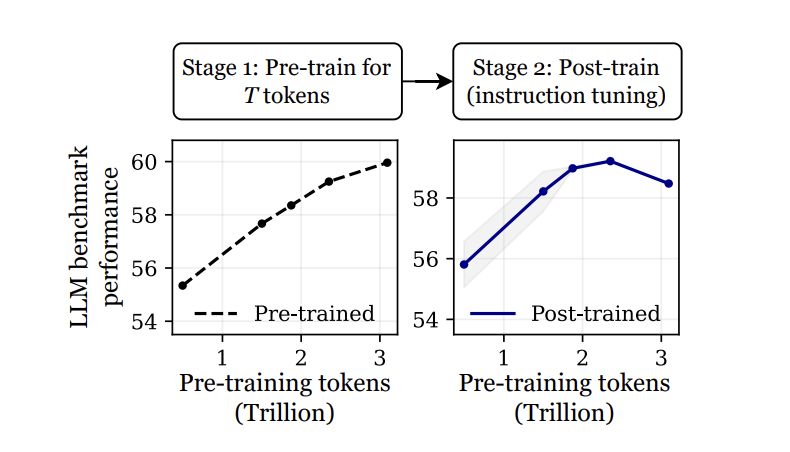
기본 모델은 사전 학습 토큰 수가 많아질수록 지속적으로 개선되는 반면, 미세조정 이후에는 일정 수준(2.3T → 3T)에서 오히려 평가 지표가 하락하는 현상이 나타났습니다.
연구진은 단순한 Gaussian 노이즈를 모델 파라미터에 추가하는 실험도 진행했는데, 사전 학습이 진행될수록 모델이 점점 더 민감해지는 progressive sensitivity 현상을 확인했습니다. 이로 인해 노이즈에 의한 성능 저하가 누적되어 결국 U자형 패턴의 퍼플렉시티 상승을 초래함을 보여주었습니다.
학습률 튜닝의 한계
고정 학습률에서는 사전 학습 토큰 수가 많아질수록 퍼플렉시티가 증가하며 성능 저하가 명확히 드러났습니다. 학습률 튜닝을 통해 최적값을 찾으려는 시도는 어느 정도 성능 저하를 완화할 수 있었으나, in-domain 태스크 성능과의 트레이드오프 문제가 발생했습니다.
이론적 분석
연구진은 두 층 선형 회귀 네트워크를 이용한 이론적 모델로 결과를 설명했습니다. 사전 학습 동안 점진적으로 새로운 특징들이 학습되며, 미세조정 단계에서 이러한 특징들이 모델의 민감도를 증가시켜 성능 저하로 이어지는 과정을 수학적으로 분석했습니다.
결론 및 시사점
이 연구의 핵심 결론은 다음과 같습니다.
"데이터가 많을수록 좋다"는 스케일링 법칙이 항상 성립하지 않는다.
사전 학습을 무조건 늘리는 것이 아니라, 사전 학습과 미세조정 간의 균형을 맞추는 것이 중요합니다. 연구진이 제안하는 완화 전략은 다음과 같습니다.
- 정규화(Regularization) 기법 적용
- 데이터 리플레이(Data Replay)
- LP-FT, WiseFT 등 분포 변화에 강인한 접근법
또한 이 현상은 미세조정뿐 아니라 모델 수정, 언러닝(Unlearning) 등 다양한 상황에서도 나타날 수 있음을 시사합니다.
개인적으로 이 논문을 읽으며 흥미로웠던 점은, 초기 Llama 테크니컬 리포트에서 "GPU 자원이 부족하니 데이터라도 많이 늘려서 학습시키면 성능을 올릴 수 있다"는 논지를 내세웠던 것과 대비된다는 점입니다. 단순히 데이터를 늘리는 것이 아닌 전체 학습 파이프라인을 고려한 새로운 스케일링 전략이 필요한 시점인 것 같습니다.